Java 面试题库
一.Java基础
运算符
1 &与&&
&和&&都可以用作逻辑与的运算符,表示逻辑与(and),当运算符两边的表达式的结果都为true时,整个运算结果才为true,否则,只要有一方为false,则结果为false。 &&还具有短路的功能,即如果第一个表达式为false,则不再计算第二个表达式,例如,对于if(str != null && !str.equals(“”))表达式,当str为null时,后面的表达式不会执行,所以不会出现NullPointerException如果将&&改为&,则会抛出NullPointerException异常。If(x==33 & ++y>0) y会增长,If(x==33 && ++y>0)不会增长 &还可以用作位运算符,当&操作符两边的表达式不是boolean类型时,&表示按位与操作,我们通常使用0x0f来与一个整数进行&运算,来获取该整数的最低4个bit位,例如,0x31 & 0x0f的结果为0x01。
2 equals和==
== 物理相等,equals逻辑相等。
==操作符专门用来比较两个变量的值是否相等,也就是用于比较变量所对应的内存中所存储的数值是否相同,要比较两个基本类型的数据或两个引用变量是否相等,只能用==操作符。 如果一个变量指向的数据是对象类型的,那么,这时候涉及了两块内存,对象本身占用一块内存(堆内存),变量也占用一块内存,例如Objet obj = new Object();变量obj是一个内存,new Object()是另一个内存,此时,变量obj所对应的内存中存储的数值就是对象占用的那块内存的首地址。对于指向对象类型的变量,如果要比较两个变量是否指向同一个对象,即要看这两个变量所对应的内存中的数值是否相等,这时候就需要用==操作符进行比较。
3、Math.round(11.5)等於多少? Math.round(-11.5)等於多少?
Math类中提供了三个与取整有关的方法:ceil、floor、round,这些方法的作用与它们的英文名称的含义相对应,例如,ceil的英文意义是天花板,该方法就表示向上取整,所以,Math.ceil(11.3)的结果为12,Math.ceil(-11.3)的结果是-11;floor的英文意义是地板,该方法就表示向下取整,所以,Math.floor(11.6)的结果为11,Math.floor(-11.6)的结果是-12;最难掌握的是round方法,它表示“四舍五入”,算法为Math.floor(x+0.5),即将原来的数字加上0.5后再向下取整,所以,Math.round(11.5)的结果为12,Math.round(-11.5)的结果为-11。
4 请说出作用域public,private,protected,以及不写时的区别
这四个作用域的可见范围如下表所示。
说明:如果在修饰的元素上面没有写任何访问修饰符,则表示friendly。

备注:只要记住了有4种访问权限,4个访问范围,然后将全选和范围在水平和垂直方向上分别按排从小到大或从大到小的顺序排列,就很容易画出上面的图了。
5、面向对象的特征有哪些方面
计算机软件系统是现实生活中的业务在计算机中的映射,而现实生活中的业务其实就是一个个对象协作的过程。面向对象编程就是按现实业务一样的方式将程序代码按一个个对象进行组织和编写,让计算机系统能够识别和理解用对象方式组织和编写的程序代码,这样就可以把现实生活中的业务对象映射到计算机系统中。 面向对象的编程语言有封装、继承 、抽象、多态等4个主要的特征。 封装: 封装是保证软件部件具有优良的模块性的基础,封装的目标就是要实现软件部件的“高内聚、低耦合”,防止程序相互依赖性而带来的变动影响。在面向对象的编程语言中,对象是封装的最基本单位,面向对象的封装比传统语言的封装更为清晰、更为有力。面向对象的封装就是把描述一个对象的属性和行为的代码封装在一个“模块”中,也就是一个类中,属性用变量定义,行为用方法进行定义,方法可以直接访问同一个对象中的属性。通常情况下,只要记住让变量和访问这个变量的方法放在一起,将一个类中的成员变量全部定义成私有的,只有这个类自己的方法才可以访问到这些成员变量,这就基本上实现对象的封装,就很容易找出要分配到这个类上的方法了,就基本上算是会面向对象的编程了。把握一个原则:把对同一事物进行操作的方法和相关的方法放在同一个类中,把方法和它操作的数据放在同一个类中。 例如,人要在黑板上画圆,这一共涉及三个对象:人、黑板、圆,画圆的方法要分配给哪个对象呢?由于画圆需要使用到圆心和半径,圆心和半径显然是圆的属性,如果将它们在类中定义成了私有的成员变量,那么,画圆的方法必须分配给圆,它才能访问到圆心和半径这两个属性,人以后只是调用圆的画圆方法、表示给圆发给消息而已,画圆这个方法不应该分配在人这个对象上,这就是面向对象的封装性,即将对象封装成一个高度自治和相对封闭的个体,对象状态(属性)由这个对象自己的行为(方法)来读取和改变。一个更便于理解的例子就是,司机将火车刹住了,刹车的动作是分配给司机,还是分配给火车,显然,应该分配给火车,因为司机自身是不可能有那么大的力气将一个火车给停下来的,只有火车自己才能完成这一动作,火车需要调用内部的离合器和刹车片等多个器件协作才能完成刹车这个动作,司机刹车的过程只是给火车发了一个消息,通知火车要执行刹车动作而已。 抽象:
抽象就是找出一些事物的相似和共性之处,然后将这些事物归为一个类,这个类只考虑这些事物的相似和共性之处,并且会忽略与当前主题和目标无关的那些方面,将注意力集中在与当前目标有关的方面。例如,看到一只蚂蚁和大象,你能够想象出它们的相同之处,那就是抽象。抽象包括行为抽象和状态抽象两个方面。例如,定义一个Person类,如下: class Person { String name; int age; } 人本来是很复杂的事物,有很多方面,但因为当前系统只需要了解人的姓名和年龄,所以上面定义的类中只包含姓名和年龄这两个属性,这就是一种抽像,使用抽象可以避免考虑一些与目标无关的细节。我对抽象的理解就是不要用显微镜去看一个事物的所有方面,这样涉及的内容就太多了,而是要善于划分问题的边界,当前系统需要什么,就只考虑什么。 继承:
在定义和实现一个类的时候,可以在一个已经存在的类的基础之上来进行,把这个已经存在的类所定义的内容作为自己的内容,并可以加入若干新的内容,或修改原来的方法使之更适合特殊的需要,这就是继承。继承是子类自动共享父类数据和方法的机制,这是类之间的一种关系,提高了软件的可重用性和可扩展性。 多态:
多态是指程序中定义的引用变量所指向的具体类型和通过该引用变量发出的方法调用在编程时并不确定,而是在程序运行期间才确定,即一个引用变量倒底会指向哪个类的实例对象,该引用变量发出的方法调用到底是哪个类中实现的方法,必须在由程序运行期间才能决定。因为在程序运行时才确定具体的类,这样,不用修改源程序代码,就可以让引用变量绑定到各种不同的类实现上,从而导致该引用调用的具体方法随之改变,即不修改程序代码就可以改变程序运行时所绑定的具体代码,让程序可以选择多个运行状态,这就是多态性。多态性增强了软件的灵活性和扩展性。
6、super.getClass()方法调用
下面程序的输出结果是多少?
import java.util.Date;
public class Test extends Date{
public static void main(String[] args) {
new Test().test();
}
public void test(){
System.out.println(super.getClass().getName());
}
}
因为super并没有代表超类的一个引用的能力,只是代表调用父类的方法而已。所以,在子类的方法中,不能这样用System.out.println(super);也不能使用super.super.mathod();
事实上,super.getClass()是表示调用父类的方法。getClass方法来自Object类,它返回对象在运行时的类型。因为在运行时的对象类型是Test,所以this.getClass()和super.getClass()都是返回Test。
String
1 String的值传递,写出如下代码运行结果
public static void main(String[] args) {
String str = new String("adcdefg");
char[] chars = {'s', 'd', 'f'};
process(str, chars);
System.out.println(str);
System.out.println(chars);
}
private static void process(String str, char[] chars) {
str = "fsdf";
chars[0] = 'a';
}
输结果应为:
adcdefg
adf
String虽然不是基本类型,但也用值传递,如果需要改变string的值,可改用StringBuilder代替。
参考http://freej.blog.51cto.com/235241/168676
Java面试中关于String的问题总结
参考http://cymoft.blog.51cto.com/324099/473220/
最后测试代码如下:
String s1 = "abc";
String s2 = "abc";
String s3 = new String("abc");//创建两个String对象,堆中创建一个String对象指向String常量池中的abc(如果存在就不在新建)
String s4 = s1.intern();//从String常量池寻找一个String,和s1 equals返回true
String s5 = s3.intern();//从String常量池寻找
System.out.println("s1==s2:" + (s1 == s2));
System.out.println("s1==s3:" + (s1 == s3));
System.out.println("s1==s4:" + (s1 == s4));
System.out.println("s1==s5:" + (s1 == s5));
输出结果:
s1==s2:true
s1==s3:false
s1==s4:true
s1==s5:true
有这样一个面试题:
String a = "a";
String a1 = new String("a");
String a2 = a1.trim() + "";
String a3 = "a" + "";
String a4 = "a".trim() + "";
System.out.println(a == a1);
System.out.println(a.intern() == a1.intern());
System.out.println(a2 == a1);
System.out.println(a3 == a);
System.out.println(a4 == a);
输出结果:
false
true
false
true
false
为什么结果是这样呢?这需要从String 本身说起。 Java在运行时会维护一个字符串常量池String Pool; 在String a=”a”; 首先检查字符串常量池中是否有”a”,如果有则直接返回,否则在常量池中创建一个新的; String a1=new String(“a”); 使用new 关键字创建的对象一定在堆栈中,同样也会维护字符串常量池,因为字符串常量池中已经存在了,则不会添加新的。在JAVA中==永远都是比较两个内存地址是否相同,这样因为a和a1不是同一个对象则已定返回false; intern()方法时返回字符串常量池中的对象,因为常量池中只存在一个“a” 则两者已定相等; a2.trim()+”” 则是在堆栈中创建了一个新对象,同时维护常量池;则该表达式返回false 但是字符串常量的拼接仅仅维护常量池不会在堆栈中创建新对象则”a”+”“还是常量池中的“a”;
3 String 和StringBuffer的区别
JAVA平台提供了两个类:String和StringBuffer,它们可以储存和操作字符串,即包含多个字符的字符数据。String类表示内容不可改变的字符串。而StringBuffer类表示内容可以被修改的字符串。当你知道字符数据要改变的时候你就可以使用StringBuffer。典型地,你可以使用StringBuffers来动态构造字符数据。另外,String实现了equals方法,new String(“abc”).equals(new String(“abc”)的结果为true,而StringBuffer没有实现equals方法,所以,new StringBuffer(“abc”).equals(new StringBuffer(“abc”)的结果为false。 接着要举一个具体的例子来说明,我们要把1到100的所有数字拼起来,组成一个串。
StringBuffer sbf = new StringBuffer();
for(int i=0;i<100;i++)
{
sbf.append(i);
}
上面的代码效率很高,因为只创建了一个StringBuffer对象,而下面的代码效率很低,因为创建了101个对象。
String str = new String();
for(int i=0;i<100;i++)
{
str = str + i;
}
在讲两者区别时,应把循环的次数搞成10000,然后用endTime-beginTime来比较两者执行的时间差异,最后还要讲讲StringBuilder与StringBuffer的区别。 String覆盖了equals方法和hashCode方法,而StringBuffer没有覆盖equals方法和hashCode方法,所以,将StringBuffer对象存储进Java集合类中时会出现问题。
4、StringBuffer与StringBuilder的区别
StringBuffer和StringBuilder类都表示内容可以被修改的字符串,StringBuilder是线程不安全的,运行效率高,如果一个字符串变量是在方法里面定义,这种情况只可能有一个线程访问它,不存在不安全的因素了,则用StringBuilder。如果要在类里面定义成员变量,并且这个类的实例对象会在多线程环境下使用,那么最好用StringBuffer。
Class
1 Class.forName和ClassLoader.loadClass的比较
Class的装载分了三个阶段,loading,linking和initializing,分别定义在The Java Language Specification的12.2,12.3和12.4。 Class.forName(className)实际上是调用Class.forName(className, true, this.getClass().getClassLoader())。注意第二个参数,是指Class被loading后是不是必须被初始化。 ClassLoader.loadClass(className)实际上调用的是ClassLoader.loadClass(name, false),第二个参数指出Class是否被link。 区别就出来了。Class.forName(className)装载的class已经被初始化,而ClassLoader.loadClass(className)装载的class还没有被link。 一般情况下,这两个方法效果一样,都能装载Class。但如果程序依赖于Class是否被初始化,就必须用Class.forName(name)了。 例如,在JDBC编程中,常看到这样的用法,Class.forName(“com.mysql.jdbc.Driver”),如果换成了getClass().getClassLoader().loadClass(“com.mysql.jdbc.Driver”),就不行。 为什么呢?打开com.mysql.jdbc.Driver的源代码看看,
// Register ourselves with the DriverManager
//
static {
try {
java.sql.DriverManager.registerDriver(new Driver());
} catch (SQLException E) {
throw new RuntimeException("Can't register driver!");
}
}
原来,Driver在static块中会注册自己到java.sql.DriverManager。而static块就是在Class的初始化中被执行。所以这个地方就只能用Class.forName(className)。
Java内存
Java内存管理
http://www.cnblogs.com/gw811/archive/2012/10/18/2730117.html
Java内存回收
http://www.cnblogs.com/gw811/archive/2012/10/19/2730258.html
http://www.cnblogs.com/sunniest/p/4575144.html
1 JAVA 垃圾回收机制
什么是垃圾回收机:释放那些不再持有引用的对象的内存 怎么判断一个对象是否需要收集?
引用计数(最简单古老的方法):指将资源(可以是对象、内存或磁盘空间等等)的被引用次数保存起来,当被引用次数变为零时就将其释放的过程
根搜索算法(现在大多数 jvm 使用的方法):对象引用遍历从一组对象开始,沿着整个对象图上的每条链接,递归确定可到达(reachable)的对象。如果某对象不能从这些根对象的一个(至少一个)到达,则将它作为垃圾收集
**几种垃圾回收机制 **
标记回收法:遍历对象图并且记录可到达的对象,以便删除不可到达的对象,一般使用单线程工作并且可能产生内存碎片
标记-压缩回收法:前期与第一种方法相同,只是多了一步,将所有的存活对象压缩到内存的一端,这样内存碎片就可以合成一大块可再利用的内存区域,提高了内存利用率
复制回收法:把现有内存空间分成两部分,gc运行时,它把可到达对象复制到另一半空间,再清空正在使用的空间的全部对象。这种方法适用于短生存期的对象,持续复制长生存期的对象则导致效率降低。
分代回收法:把内存空间分为两个或者多个域,如年轻代和老年代,年轻代的特点是对象会很快被回收,因此在年轻代使用效率比较高复制回收的算法。当一个对象经过几次回收后依然存活,对象就会被放入称为老年的内存空间,老年代则采取标记-压缩算法
Android
Framework
1 Dalvik VM (DVM) 与Java VM (JVM)之间有哪些区别?
Dalvik虚拟机是Google等厂商合作开发的Android移动设备平台的核心组成部分之一。它可以支持已转换为.dex(即Dalvik Executable)格式的Java应用程序的运行,.dex格式是专为Dalvik设计的一种压缩格式,适合内存和处理器速度有限的系统。(dx 是一套工具,可以将 Java .class 转换成 .dex 格式. 一个dex档通常会有多个.class。由于dex有时必须进行最佳化,会使档案大小增加1-4倍,以ODEX结尾。)
1、Dalvik 和标准 Java 虚拟机(JVM)的首要差别
Dalvik 基于寄存器,而 JVM 基于栈。基于寄存器的虚拟机对于更大的程序来说,在它们编译的时候,花费的时间更短。 JVM字节码中,局部变量会被放入局部变量表中,继而被压入堆栈供操作码进行运算,当然JVM也可以只使用堆栈而不显式地将局部变量存入变量表中。Dalvik字节码中,局部变量会被赋给65536个可用的寄存器中的任何一个,Dalvik指令直接操作这些寄存器,而不是访问堆栈中的元素。
2、Dalvik 和 Java 字节码的区别
VM字节码由.class文件组成,每个文件一个class。JVM在运行的时候为每一个类装载字节码。相反的,Dalvik程序只包含一个.dex文件,这个文件包含了程序中所有的类。Java编译器创建了JVM字节码之后,Dalvik的dx编译器删除.class文件,重新把它们编译成Dalvik字节码,然后把它们写进一个.dex文件中。这个过程包括翻译、重构、解释程序的基本元素(常量池、类定义、数据段)。常量池描述了所有的常量,包括引用、方法名、数值常量等。类定义包括了访问标志、类名等基本信息。数据段中包含各种被VM执行的函数代码以及类和函数的相关信息(例如DVM所需要的寄存器数量、局部变量表、操作数堆栈大小),还有实例变量。

3、Dalvik 和 Java SDK的SDK不同。
4、Dalvik 和 Java 运行环境的区别
Dalvik 经过优化,允许在有限的内存中同时运行多个虚拟机的实例,并且每一个Dalvik 应用作为一个独立的Linux 进程执行。独立的进程可以防止在虚拟机崩溃的时候所有程序都被关闭。
Dalvik虚拟机在android2.2之后使用JIT (Just-In-Time)技术,与传统JVM的JIT并不完全相同,
Dalvik虚拟机有自己的 bytecode,并非使用 Java bytecode。
还有以下几点:
1、Dalvik主要是完成对象生命周期管理,堆栈管理,线程管理,安全和异常管理,以及垃圾回收等等重要功能。
2、Dalvik负责进程隔离和线程管理,每一个Android应用在底层都会对应一个独立的Dalvik虚拟机实例,其代码在虚拟机的解释下得以执行。
3、不同于Java虚拟机运行java字节码,Dalvik虚拟机运行的是其专有的文件格式Dex。
4、dex文件格式可以减少整体文件尺寸,提高I/O操作的类查找速度。
5、odex是为了在运行过程中进一步提高性能,对dex文件的进一步优化。
6、所有的Android应用的线程都对应一个Linux线程,虚拟机因而可以更多的依赖操作系统的线程调度和管理机制。
7、有一个特殊的虚拟机进程Zygote,他是虚拟机实例的孵化器。它在系统启动的时候就会产生,它会完成虚拟机的初始化、库的加载、预制类库和初始化的操作。如果系统需要一个新的虚拟机实例,它会迅速复制自身,以最快的速度提供给系统。对于一些只读的系统库,所有虚拟机实例都和Zygote共享一块内存区域。 参考
http://www.cnblogs.com/yejiurui/p/4859892.html
https://www.zhihu.com/question/20207106
2 Dalvik和ART的区别
什么是Dalvik: Dalvik是Google公司自己设计用于Android平台的Java虚拟机。Dalvik虚拟机是Google等厂商合作开发的Android移动设备平台的核心组成部分之一。它可以支持已转换为 .dex(即Dalvik Executable)格式的Java应用程序的运行,.dex格式是专为Dalvik设计的一种压缩格式,适合内存和处理器速度有限的系统。Dalvik 经过优化,允许在有限的内存中同时运行多个虚拟机的实例,并且每一个Dalvik 应用作为一个独立的Linux 进程执行。独立的进程可以防止在虚拟机崩溃的时候所有程序都被关闭。
什么是ART: Android操作系统已经成熟,Google的Android团队开始将注意力转向一些底层组件,其中之一是负责应用程序运行的Dalvik运行时。Google开发者已经花了两年时间开发更快执行效率更高更省电的替代ART运行时。 ART代表Android Runtime,其处理应用程序执行的方式完全不同于Dalvik,Dalvik是依靠一个Just-In-Time (JIT)编译器去解释字节码。开发者编译后的应用代码需要通过一个解释器在用户的设备上运行,这一机制并不高效,但让应用能更容易在不同硬件和架构上运 行。ART则完全改变了这套做法,在应用安装时就预编译字节码到机器语言,这一机制叫Ahead-Of-Time (AOT)编译。在移除解释代码这一过程后,应用程序执行将更有效率,启动更快。
ART优点: 1、系统性能的显著提升。 2、应用启动更快、运行更快、体验更流畅、触感反馈更及时。 3、更长的电池续航能力。
4、支持更低的硬件。
ART缺点: 1、更大的存储空间占用,可能会增加10%-20%。 2、更长的应用安装时间。
总的来说ART的功效就是“空间换时间”。
Android性能优化
1 省电优化
使用WakeLock或者JobScheduler唤醒设备处理定时的任务之后,一定要及时让设备回到初始状态。每次唤醒蜂窝信号进行数据传递,都会消耗很多电量,它比WiFi等操作更加的耗电。
2 Battery Historian
Battery Historian是Android 5.0开始引入的新API。通过下面的指令,可以得到设备上的电量消耗信息:
$ adb shell dumpsys batterystats > xxx.txt //得到整个设备的电量消耗信息
$ adb shell dumpsys batterystats > com.package.name > xxx.txt //得到指定app相关的电量消耗信息
得到了原始的电量消耗数据之后,我们需要通过Google编写的一个python脚本把数据信息转换成可读性更好的html文件:
$ python historian.py xxx.txt > xxx.html
打开这个转换过后的html文件,可以看到类似TraceView生成的列表数据,这里的数据信息量很大,这里就不展开了。

3 Track Battery Status & Battery Manager
我们可以通过下面的代码来获取手机的当前充电状态:
// It is very easy to subscribe to changes to the battery state, but you can get the current
// state by simply passing null in as your receiver. Nifty, isn't that?
IntentFilter filter = new IntentFilter(Intent.ACTION_BATTERY_CHANGED);
Intent batteryStatus = this.registerReceiver(null, filter);
int chargePlug = batteryStatus.getIntExtra(BatteryManager.EXTRA_PLUGGED, -1);
boolean acCharge = (chargePlug == BatteryManager.BATTERY_PLUGGED_AC);
if (acCharge) {
Log.v(LOG_TAG,“The phone is charging!”);
}
在上面的例子演示了如何立即获取到手机的充电状态,得到充电状态信息之后,我们可以有针对性的对部分代码做优化。比如我们可以判断只有当前手机为AC充电状态时 才去执行一些非常耗电的操作。
/**
* This method checks for power by comparing the current battery state against all possible
* plugged in states. In this case, a device may be considered plugged in either by USB, AC, or
* wireless charge. (Wireless charge was introduced in API Level 17.)
*/
private boolean checkForPower() {
// It is very easy to subscribe to changes to the battery state, but you can get the current
// state by simply passing null in as your receiver. Nifty, isn't that?
IntentFilter filter = new IntentFilter(Intent.ACTION_BATTERY_CHANGED);
Intent batteryStatus = this.registerReceiver(null, filter);
// There are currently three ways a device can be plugged in. We should check them all.
int chargePlug = batteryStatus.getIntExtra(BatteryManager.EXTRA_PLUGGED, -1);
boolean usbCharge = (chargePlug == BatteryManager.BATTERY_PLUGGED_USB);
boolean acCharge = (chargePlug == BatteryManager.BATTERY_PLUGGED_AC);
boolean wirelessCharge = false;
if (Build.VERSION.SDK_INT >= Build.VERSION_CODES.JELLY_BEAN_MR1) {
wirelessCharge = (chargePlug == BatteryManager.BATTERY_PLUGGED_WIRELESS);
}
return (usbCharge || acCharge || wirelessCharge);
}
4 Wakelock and Battery Drain
假设你的手机里面装了大量的社交类应用,即使手机处于待机状态,也会经常被这些应用唤醒用来检查同步新的数据信息。Android会不断关闭各种硬件来延长手机的待机时间,首先屏幕会逐渐变暗直至关闭,然后CPU进入睡眠,这一切操作都是为了节约宝贵的电量资源。但是即使在这种睡眠状态下,大多数应用还是会尝试进行工作,他们将不断的唤醒手机。一个最简单的唤醒手机的方法是使用PowerManager.WakeLock的API来保持CPU工作并防止屏幕变暗关闭。这使得手机可以被唤醒,执行工作,然后回到睡眠状态。知道如何获取WakeLock是简单的,可是及时释放WakeLock也是非常重要的,不恰当的使用WakeLock会导致严重错误。例如网络请求的数据返回时间不确定,导致本来只需要10s的事情一直等待了1个小时,这样会使得电量白白浪费了。这也是为何使用带超时参数的wakelock.acquice()方法是很关键的。
但是仅仅设置超时并不足够解决问题,例如设置多长的超时比较合适?什么时候进行重试等等?解决上面的问题,正确的方式可能是使用非精准定时器。通常情况下,我们会设定一个时间进行某个操作,但是动态修改这个时间也许会更好。例如,如果有另外一个程序需要比你设定的时间晚5分钟唤醒,最好能够等到那个时候,两个任务捆绑一起同时进行,这就是非精确定时器的核心工作原理。我们可以定制计划的任务,可是系统如果检测到一个更好的时间,它可以推迟你的任务,以节省电量消耗。

这正是JobScheduler API所做的事情。它会根据当前的情况与任务,组合出理想的唤醒时间,例如等到正在充电或者连接到WiFi的时候,或者集中任务一起执行。我们可以通过这个API实现很多免费的调度算法。
总之,为了减少电量的消耗,在蜂窝移动网络下,最好做到批量执行网络请求,尽量避免频繁的间隔网络请求。
通过前面学习到的Battery Historian我们可以得到设备的电量消耗数据,如果数据中的移动蜂窝网络(Mobile Radio)电量消耗呈现下面的情况,间隔很小,又频繁断断续续的出现,说明电量消耗性能很不好:

经过优化之后,如果呈现下面的图示,说明电量消耗的性能是良好的:

另外WiFi连接下,网络传输的电量消耗要比移动网络少很多,应该尽量减少移动网络下的数据传输,多在WiFi环境下传输数据。

那么如何才能够把任务缓存起来,做到批量化执行呢?下面就轮到Job Scheduler出场了。
Using Job Scheduler
使用Job Scheduler,应用需要做的事情就是判断哪些任务是不紧急的,可以交给Job Scheduler来处理,Job Scheduler集中处理收到的任务,选择合适的时间,合适的网络,再一起进行执行。
下面是使用Job Scheduler的一段简要示例,需要先有一个JobService:
public class MyJobService extends JobService {
private static final String LOG_TAG = "MyJobService";
@Override
public void onCreate() {
super.onCreate();
Log.i(LOG_TAG, "MyJobService created");
}
@Override
public void onDestroy() {
super.onDestroy();
Log.i(LOG_TAG, "MyJobService destroyed");
}
@Override
public boolean onStartJob(JobParameters params) {
// This is where you would implement all of the logic for your job. Note that this runs
// on the main thread, so you will want to use a separate thread for asynchronous work
// (as we demonstrate below to establish a network connection).
// If you use a separate thread, return true to indicate that you need a "reschedule" to
// return to the job at some point in the future to finish processing the work. Otherwise,
// return false when finished.
Log.i(LOG_TAG, "Totally and completely working on job " + params.getJobId());
// First, check the network, and then attempt to connect.
if (isNetworkConnected()) {
new SimpleDownloadTask() .execute(params);
return true;
} else {
Log.i(LOG_TAG, "No connection on job " + params.getJobId() + "; sad face");
}
return false;
}
@Override
public boolean onStopJob(JobParameters params) {
// Called if the job must be stopped before jobFinished() has been called. This may
// happen if the requirements are no longer being met, such as the user no longer
// connecting to WiFi, or the device no longer being idle. Use this callback to resolve
// anything that may cause your application to misbehave from the job being halted.
// Return true if the job should be rescheduled based on the retry criteria specified
// when the job was created or return false to drop the job. Regardless of the value
// returned, your job must stop executing.
Log.i(LOG_TAG, "Whelp, something changed, so I'm calling it on job " + params.getJobId());
return false;
}
/**
* Determines if the device is currently online.
*/
private boolean isNetworkConnected() {
ConnectivityManager connectivityManager =
(ConnectivityManager) getSystemService(Context.CONNECTIVITY_SERVICE);
NetworkInfo networkInfo = connectivityManager.getActiveNetworkInfo();
return (networkInfo != null && networkInfo.isConnected());
}
/**
* Uses AsyncTask to create a task away from the main UI thread. This task creates a
* HTTPUrlConnection, and then downloads the contents of the webpage as an InputStream.
* The InputStream is then converted to a String, which is logged by the
* onPostExecute() method.
*/
private class SimpleDownloadTask extends AsyncTask<JobParameters, Void, String> {
protected JobParameters mJobParam;
@Override
protected String doInBackground(JobParameters... params) {
// cache system provided job requirements
mJobParam = params[0];
try {
InputStream is = null;
// Only display the first 50 characters of the retrieved web page content.
int len = 50;
URL url = new URL("https://www.google.com");
HttpURLConnection conn = (HttpURLConnection) url.openConnection();
conn.setReadTimeout(10000); //10sec
conn.setConnectTimeout(15000); //15sec
conn.setRequestMethod("GET");
//Starts the query
conn.connect();
int response = conn.getResponseCode();
Log.d(LOG_TAG, "The response is: " + response);
is = conn.getInputStream();
// Convert the input stream to a string
Reader reader = null;
reader = new InputStreamReader(is, "UTF-8");
char[] buffer = new char[len];
reader.read(buffer);
return new String(buffer);
} catch (IOException e) {
return "Unable to retrieve web page.";
}
}
@Override
protected void onPostExecute(String result) {
jobFinished(mJobParam, false);
Log.i(LOG_TAG, result);
}
}
}
然后模拟通过点击Button触发N个任务,交给JobService来处理
public class FreeTheWakelockActivity extends ActionBarActivity {
public static final String LOG_TAG = "FreeTheWakelockActivity";
TextView mWakeLockMsg;
ComponentName mServiceComponent;
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_wakelock);
mWakeLockMsg = (TextView) findViewById(R.id.wakelock_txt);
mServiceComponent = new ComponentName(this, MyJobService.class);
Intent startServiceIntent = new Intent(this, MyJobService.class);
startService(startServiceIntent);
Button theButtonThatWakelocks = (Button) findViewById(R.id.wakelock_poll);
theButtonThatWakelocks.setText(R.string.poll_server_button);
theButtonThatWakelocks.setOnClickListener(new View.OnClickListener() {
@Override
public void onClick(View v) {
pollServer();
}
});
}
/**
* This method polls the server via the JobScheduler API. By scheduling the job with this API,
* your app can be confident it will execute, but without the need for a wake lock. Rather, the
* API will take your network jobs and execute them in batch to best take advantage of the
* initial network connection cost.
*
* The JobScheduler API works through a background service. In this sample, we have
* a simple service in MyJobService to get you started. The job is scheduled here in
* the activity, but the job itself is executed in MyJobService in the startJob() method. For
* example, to poll your server, you would create the network connection, send your GET
* request, and then process the response all in MyJobService. This allows the JobScheduler API
* to invoke your logic without needed to restart your activity.
*
* For brevity in the sample, we are scheduling the same job several times in quick succession,
* but again, try to consider similar tasks occurring over time in your application that can
* afford to wait and may benefit from batching.
*/
public void pollServer() {
JobScheduler scheduler = (JobScheduler) getSystemService(Context.JOB_SCHEDULER_SERVICE);
for (int i=0; i<10; i++) {
JobInfo jobInfo = new JobInfo.Builder(i, mServiceComponent)
.setMinimumLatency(5000) // 5 seconds
.setOverrideDeadline(60000) // 60 seconds (for brevity in the sample)
.setRequiredNetworkType(JobInfo.NETWORK_TYPE_ANY) // WiFi or data connections
.build();
mWakeLockMsg.append("Scheduling job " + i + "!\n");
scheduler.schedule(jobInfo);
}
}
}
高德面试题
1 编程实现一个函数,输入为一个奇数n,(1)输出为n*n的正方形,每个元素为字母A;(2)输出一个菱形,该菱形满足:中间一行为n个元素,像上下两个方向逐层递减2个元素个数,第一行和最后一行都为1.
分析:这类题一般都是用二维数组来解,正方形没什么问题,菱形打印:一行一行填充数组,定义low和high两个指针,初始指向中间位置mid,索引处在low和high中间填充为1 ,根据行数,改变low和high的位置,最后打印数组,代码实现如下:
private static void printRhomb(int n) {
if (n % 2 == 0) {
return;
}
int[][] postions = new int[n][n];
int mid = n / 2;
for (int i = 0, low = mid, high = mid; i < postions.length; i++) {
int[] row = postions[i];
for (int j = 0; j < row.length; j++) {
if (j >= low && j <= high)
row[j] = 1;
if (row[j] == 1) {
System.out.print('*');
} else {
System.out.print(" ");
}
}
if (i < mid) {
low--;
high++;
} else {
low++;
high--;
}
System.out.println();
}
}
输入11,输出如下:
*
***
*****
*******
*********
***********
*********
*******
*****
***
*
2 dialog的context能否用Application?
答案应该是不可以,会报如下错误:
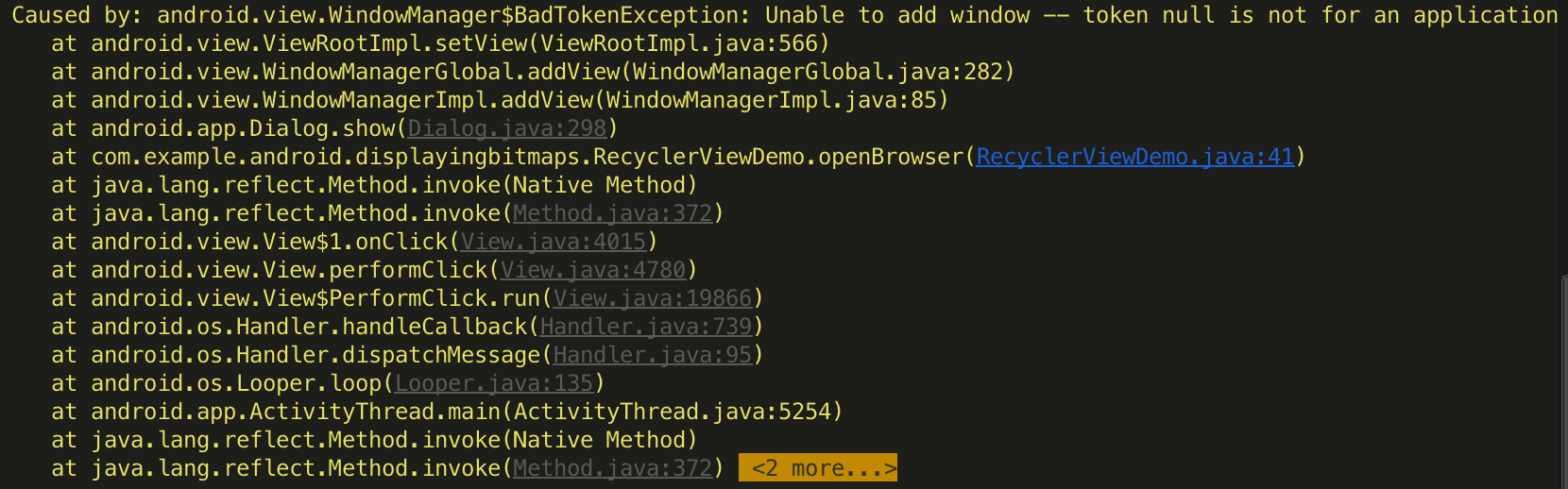
根据日志可以知道在android.view.ViewRootImpl.setView()方法中抛出了该运行时异常。
可在android源码中查找该类的setView方法,
发现如下代码:
if (res < WindowManagerGlobal.ADD_OKAY) {
mAttachInfo.mRootView = null;
mAdded = false;
mFallbackEventHandler.setView(null);
unscheduleTraversals();
setAccessibilityFocus(null, null);
switch (res) {
case WindowManagerGlobal.ADD_BAD_APP_TOKEN:
case WindowManagerGlobal.ADD_BAD_SUBWINDOW_TOKEN:
throw new WindowManager.BadTokenException(
"Unable to add window -- token " + attrs.token
+ " is not valid; is your activity running?");
case WindowManagerGlobal.ADD_NOT_APP_TOKEN:
throw new WindowManager.BadTokenException(
"Unable to add window -- token " + attrs.token
+ " is not for an application");
而WindowManagerGlobal.ADD_OKAY的值为0.
3 在没有代码的情况下,如何查看某一app中某一变量的当前值?
当时回答的是,在sd卡放置文件作为log开关,面试官想要更简单的答案,事后问了下,答案是可以获取该进程的内存快照,通过heap查找该变量所在的对象,即可看到该对象所有属性的值,as中就可以完成。
获取内存快照后,选择相关对象,在instance窗口就可以看到该对象所有属性值。
4 内部类能否访问外部类私有变量?
答案是肯定的,非静态内部类会持有一个外部类的引用,可以在内部类内部访问外部类的一起属性,无论内部类有没有访问外部类的属性。下图例子外部类为Printrhomb:
public class Printrhomb {
private int outInt;
public static void main(String[] args) {
InnerClass innerClass = new Printrhomb().new InnerClass();
}
class InnerClass {
public void test() {
System.out.println(outInt);
}
}
}
实例化一个内部类后,通过断点观察该内部类的成员变量:

有一个对外部类实例的引用,名字为this$0.
5 intent传递数据大小有没有限制?
大小肯定是有限制的,因为手机内存空间是有限的嘛。具体是多少,不太确定,实际测试中利用intent传递了一个bitmap对象,大概有20M,点击启动activity后,界面无响应。网上说会抛出TransactionTooLargeException,这个异常中说大小限制为1MB,实际测试并未抛出异常,而是无响应。logcat中可以看到:
07-22 15:25:46.830 2339-2339/com.example.android.displayingbitmaps E/JavaBinder: !!! FAILED BINDER TRANSACTION !!!
07-22 15:27:59.341 2339-2339/com.example.android.displayingbitmaps E/JavaBinder: !!! FAILED BINDER TRANSACTION !!!
说明intent也是通过binder来进行传递数据的。
6 什么是泛型擦除?
前面已经说了,Java的泛型是伪泛型。为什么说Java的泛型是伪泛型呢?因为,在编译期间,所有的泛型信息都会被擦除掉。正确理解泛型概念的首要前提是理解类型擦出(type erasure)。
Java中的泛型基本上都是在编译器这个层次来实现的。在生成的Java字节码中是不包含泛型中的类型信息的。使用泛型的时候加上的类型参数,会在编译器在编译的时候去掉。这个过程就称为类型擦除。
参考
http://blog.csdn.net/lonelyroamer/article/details/7868820
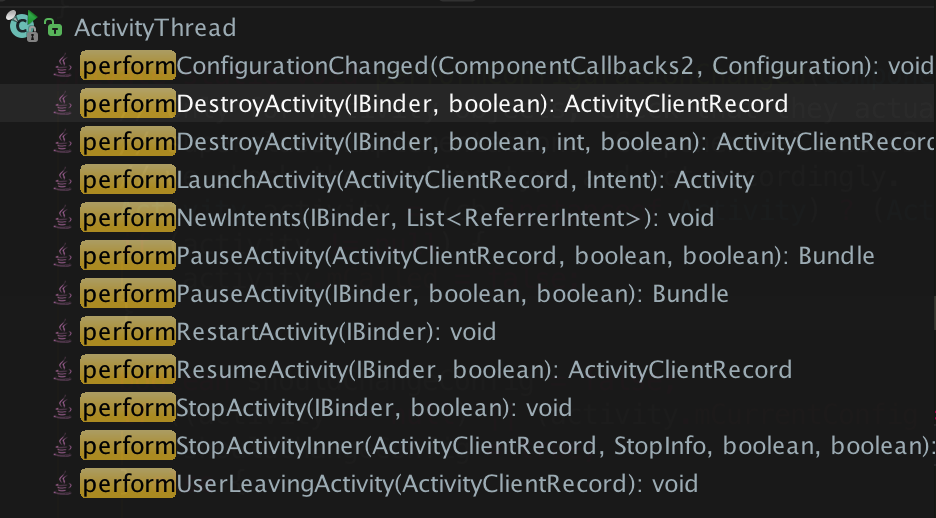
7 activity生命周期的回调者是谁?
通过断点可以发现是在ActivityThread类中,有一系列与Activity生命周期对应的方法:
8 aidl通信是同步还是异步?如何实现异步通信?
aidl是Android Interface Description Language的简称,