基于Android 6.0的源码剖析,在讲解Binder原理之前,先从kernel的角度来讲解Binder Driver.
/kernel/drivers/android/binder.c
/kernel/include/uapi/linux/android/binder.h
一、Binder通信简述
上一篇文章Binder Driver初探介绍了Binder驱动的init、open、mmap、ioctl这4个核心方法,并说明与Binder相关的常见结构体。
Client进程通过RPC(Remote Procedure Call Protocol)与Server通信,可以简单地划分为三层,驱动层、IPC层、业务层。demo()便是Client端和Server共同协商好的统一方法;handle、RPC数据、代码、协议这4项组成了IPC层的数据,通过IPC层进行数据传输;而真正在Client和Server两端建立通信的基础设施便是Binder Driver。
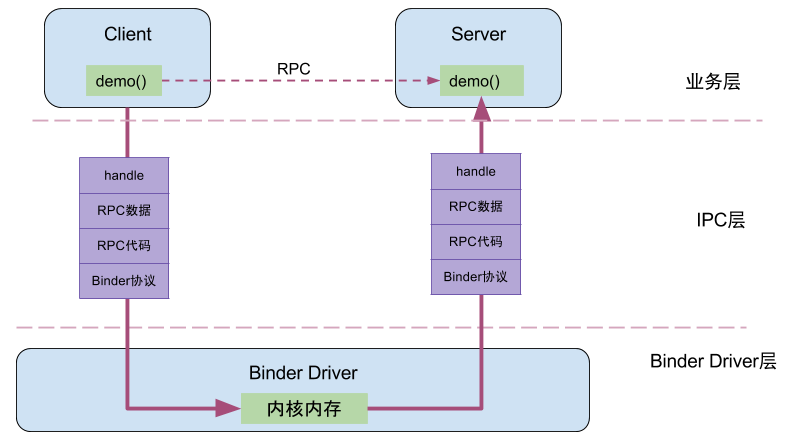
例如,当名为BatteryStatsService的Client向ServiceManager注册服务的过程中,IPC层的数据组成为:Handle=0,RPC代码为ADD_SERVICE_TRANSACTION,RPC数据为BatteryStatsService,Binder协议为BC_TRANSACTION。
二、Binder通信协议
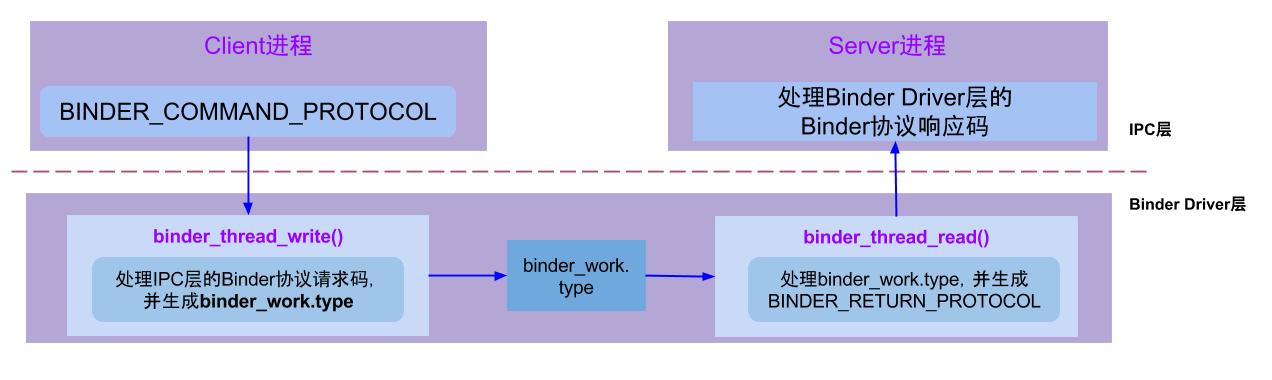
Binder协议包含在IPC数据中,分为两类:
BINDER_COMMAND_PROTOCOL:binder请求码,以”BC_“开头,简称BC码,用于从IPC层传递到Binder Driver层;BINDER_RETURN_PROTOCOL:binder响应码,以”BR_“开头,简称BR码,用于从Binder Driver层传递到IPC层;
2.1 请求协议
binder请求码,是用enum binder_driver_command_protocol来定义的,是用于应用程序向binder驱动设备发送请求消息,应用程序包含Client端和Server端,以BC_开头,总17条;(-代表目前不支持的请求码)
| 请求码 | 参数类型 | 作用 |
|---|---|---|
| BC_TRANSACTION | binder_transaction_data | Client向Binder驱动发送请求数据 |
| BC_REPLY | binder_transaction_data | Server向Binder驱动发送请求数据 |
| BC_FREE_BUFFER | binder_uintptr_t(指针) | 释放内存 |
| BC_INCREFS | __u32(descriptor) | binder_ref弱引用加1操作 |
| BC_DECREFS | __u32(descriptor) | binder_ref弱引用减1操作 |
| BC_ACQUIRE | __u32(descriptor) | binder_ref强引用加1操作 |
| BC_RELEASE | __u32(descriptor) | binder_ref强引用减1操作 |
| BC_ACQUIRE_DONE | binder_ptr_cookie | binder_node强引用减1操作 |
| BC_INCREFS_DONE | binder_ptr_cookie | binder_node弱引用减1操作 |
| BC_REGISTER_LOOPER | 无参数 | 创建新的looper线程 |
| BC_ENTER_LOOPER | 无参数 | 应用线程进入looper |
| BC_EXIT_LOOPER | 无参数 | 应用线程退出looper |
| BC_REQUEST_DEATH_NOTIFICATION | binder_handle_cookie | 接受指定binder的死亡通知 |
| BC_CLEAR_DEATH_NOTIFICATION | binder_handle_cookie | 不再接受指定binder的死亡通知 |
| BC_DEAD_BINDER_DONE | binder_uintptr_t(指针) | 已完成binder的死亡通知 |
| BC_ACQUIRE_RESULT | - | - |
| BC_ATTEMPT_ACQUIRE | - | - |
- BC_FREE_BUFFER:通过mmap()映射内存,其中ServiceManager映射的空间大小为128K,其他Binder应用进程映射的内存大小为1M-8K。Binder驱动基于这块映射的内存采用最佳匹配算法来动态分配和释放,通过binder_buffer结构体中的
free字段来表示相应的buffer是空闲还是已分配状态。对于已分配的buffers加入到binder_proc中的allocated_buffers红黑树;对于空闲的buffers加入到binder_proc中的free_buffers红黑树。当应用程序需要内存时,根据所需内存大小从free_buffers中找到最合适的内存,并放入allocated_buffers树;当应用程序处理完后必须尽快使用BC_FREE_BUFFER命令来释放该buffer,从而添加回到free_buffers树中。 - BC_INCREFS、BC_ACQUIRE、BC_RELEASE、BC_DECREFS等请求码的作用是对binder的强/弱引用的计数操作,用于实现强/弱指针的功能。
- 对于参数类型
binder_ptr_cookie是由binder指针和cookie组成。 - Binder线程创建与退出:
- BC_ENTER_LOOPER:binder主线程(由应用层发起)的创建会向驱动发送该消息;
- BC_REGISTER_LOOPER:Binder用于驱动层决策而创建新的binder线程;
- BC_EXIT_LOOPER:退出Binder线程,对于binder主线程是不能退出。
2.2 请求过程
请求处理过程是通过binder_thread_write()方法,该方法用于处理Binder协议中的请求码。当binder_buffer存在数据,binder线程的写操作循环执行。
binder_thread_write(){
while (ptr < end && thread->return_error == BR_OK) {
get_user(cmd, (uint32_t __user *)ptr);//获取IPC数据中的Binder协议(BC码)
switch (cmd) {
case BC_INCREFS:
case BC_ACQUIRE:
case BC_RELEASE:
case BC_DECREFS:
get_user(target, (uint32_t __user *)ptr);//获取IPC数据中的handle
if (target == 0 && binder_context_mgr_node &&
(cmd == BC_INCREFS || cmd == BC_ACQUIRE)) {
//查找service manager的binder_ref
ref = binder_get_ref_for_node(proc, binder_context_mgr_node);
} else {
//根据target查找binder_ref
ref = binder_get_ref(proc, target);
}
//根据不同cmd,对ref进行相应的增减操作,见BC码表。省略。。。
break;
case BC_INCREFS_DONE:
case BC_ACQUIRE_DONE:
get_user(node_ptr, (binder_uintptr_t __user *)ptr)
get_user(cookie, (binder_uintptr_t __user *)ptr)
//根据节点指针node_ptr,获取相应的binder_node
node = binder_get_node(proc, node_ptr);
//根据不同的cmd, 对node进行相应的增减操作,见BC码表。省略。。。
break;
case BC_FREE_BUFFER:
get_user(data_ptr, (binder_uintptr_t __user *)ptr);
//根据buffer指针data_ptr,查找相应的binder_buffer
buffer = binder_buffer_lookup(proc, data_ptr);
if (buffer->transaction) {
buffer->transaction->buffer = NULL;
buffer->transaction = NULL;
}
//释放相应的buffer,以及将新的buffer加入到可用buffer队列中
binder_transaction_buffer_release(proc, buffer, NULL);
binder_free_buf(proc, buffer);
break;
case BC_TRANSACTION:
case BC_REPLY: {
struct binder_transaction_data tr;
copy_from_user(&tr, ptr, sizeof(tr)); //拷贝用户空间tr到内核
// 执行binder_transaction操作
binder_transaction(proc, thread, &tr, cmd == BC_REPLY);
break;
case BC_REGISTER_LOOPER:
proc->requested_threads--;
proc->requested_threads_started++;
thread->looper |= BINDER_LOOPER_STATE_REGISTERED;
break;
case BC_ENTER_LOOPER:
thread->looper |= BINDER_LOOPER_STATE_ENTERED;
break;
case BC_EXIT_LOOPER:
thread->looper |= BINDER_LOOPER_STATE_EXITED;
break;
case BC_REQUEST_DEATH_NOTIFICATION:
case BC_CLEAR_DEATH_NOTIFICATION: {
get_user(target, (uint32_t __user *)ptr);
get_user(cookie, (binder_uintptr_t __user *)ptr);
ref = binder_get_ref(proc, target);
if (cmd == BC_REQUEST_DEATH_NOTIFICATION) {
death = kzalloc(sizeof(*death), GFP_KERNEL);
ref->death = death;
if (ref->node->proc == NULL) {
ref->death->work.type = BINDER_WORK_DEAD_BINDER;
list_add_tail(&ref->death->work.entry, &thread->todo);
}
}else{
if (list_empty(&death->work.entry)) {
death->work.type = BINDER_WORK_CLEAR_DEATH_NOTIFICATION;
list_add_tail(&ref->death->work.entry, &thread->todo);
} else {
death->work.type = BINDER_WORK_DEAD_BINDER_AND_CLEAR;
}
}
break;
case BC_DEAD_BINDER_DONE:
get_user(cookie, (binder_uintptr_t __user *)ptr);
list_for_each_entry(w, &proc->delivered_death, entry) {
struct binder_ref_death *tmp_death = container_of(w, struct binder_ref_death, work);
if (tmp_death->cookie == cookie) {
death = tmp_death;
break;
}
}
list_del_init(&death->work.entry);
if (death->work.type == BINDER_WORK_DEAD_BINDER_AND_CLEAR) {
death->work.type = BINDER_WORK_CLEAR_DEATH_NOTIFICATION;
list_add_tail(&death->work.entry, &thread->todo);
}
break;
}
}
}
}
2.3 事务处理
对于请求码为BC_TRANSACTION或BC_REPLY时,会执行binder_transaction()方法,该方法比较核心,代码如下:
static void binder_transaction(struct binder_proc *proc,
struct binder_thread *thread,
struct binder_transaction_data *tr, int reply){
if (reply) {
in_reply_to = thread->transaction_stack;
binder_set_nice(in_reply_to->saved_priority);
thread->transaction_stack = in_reply_to->to_parent;
target_thread = in_reply_to->from;
target_proc = target_thread->proc;
}else {
if (tr->target.handle) {
struct binder_ref *ref;
ref = binder_get_ref(proc, tr->target.handle);
target_node = ref->node;
} else {
target_node = binder_context_mgr_node;
}
target_proc = target_node->proc;
if (!(tr->flags & TF_ONE_WAY) && thread->transaction_stack) {
struct binder_transaction *tmp;
tmp = thread->transaction_stack;
while (tmp) {
if (tmp->from && tmp->from->proc == target_proc)
target_thread = tmp->from;
tmp = tmp->from_parent;
}
}
}
if (target_thread) {
e->to_thread = target_thread->pid;
target_list = &target_thread->todo;
target_wait = &target_thread->wait;
} else {
target_list = &target_proc->todo;
target_wait = &target_proc->wait;
}
t = kzalloc(sizeof(*t), GFP_KERNEL);
tcomplete = kzalloc(sizeof(*tcomplete), GFP_KERNEL);
if (!reply && !(tr->flags & TF_ONE_WAY))
t->from = thread;
else
t->from = NULL;
t->sender_euid = task_euid(proc->tsk);
t->to_proc = target_proc;
t->to_thread = target_thread;
t->code = tr->code;
t->flags = tr->flags;
t->priority = task_nice(current);
t->buffer = binder_alloc_buf(target_proc, tr->data_size,
tr->offsets_size, !reply && (t->flags & TF_ONE_WAY));
t->buffer->allow_user_free = 0;
t->buffer->transaction = t;
t->buffer->target_node = target_node;
if (target_node)
binder_inc_node(target_node, 1, 0, NULL);
offp = (binder_size_t *)(t->buffer->data + ALIGN(tr->data_size, sizeof(void *)));
copy_from_user(t->buffer->data, (const void __user *)(uintptr_t)tr->data.ptr.buffer, tr->data_size);
copy_from_user(offp, (const void __user *)(uintptr_t)tr->data.ptr.offsets, tr->offsets_size);
off_end = (void *)offp + tr->offsets_size;
for (; offp < off_end; offp++) {
struct flat_binder_object *fp;
fp = (struct flat_binder_object *)(t->buffer->data + *offp);
off_min = *offp + sizeof(struct flat_binder_object);
switch (fp->type) {
case BINDER_TYPE_BINDER:
case BINDER_TYPE_WEAK_BINDER: {
struct binder_ref *ref;
struct binder_node *node = binder_get_node(proc, fp->binder);
if (node == NULL) { //创建binder_node节点
node = binder_new_node(proc, fp->binder, fp->cookie);
}
ref = binder_get_ref_for_node(target_proc, node);
if (fp->type == BINDER_TYPE_BINDER)
fp->type = BINDER_TYPE_HANDLE;
else
fp->type = BINDER_TYPE_WEAK_HANDLE;
fp->handle = ref->desc;
binder_inc_ref(ref, fp->type == BINDER_TYPE_HANDLE,
&thread->todo);
} break;
case BINDER_TYPE_HANDLE:
case BINDER_TYPE_WEAK_HANDLE: {
struct binder_ref *ref = binder_get_ref(proc, fp->handle);
if (ref->node->proc == target_proc) {
if (fp->type == BINDER_TYPE_HANDLE)
fp->type = BINDER_TYPE_BINDER;
else
fp->type = BINDER_TYPE_WEAK_BINDER;
fp->binder = ref->node->ptr;
fp->cookie = ref->node->cookie;
binder_inc_node(ref->node, fp->type == BINDER_TYPE_BINDER, 0, NULL);
} else {
struct binder_ref *new_ref;
new_ref = binder_get_ref_for_node(target_proc, ref->node);
fp->handle = new_ref->desc;
binder_inc_ref(new_ref, fp->type == BINDER_TYPE_HANDLE, NULL);
trace_binder_transaction_ref_to_ref(t, ref, new_ref);
}
} break;
case BINDER_TYPE_FD: {
int target_fd;
struct file *file;
file = fget(fp->handle);
target_fd = task_get_unused_fd_flags(target_proc, O_CLOEXEC);
task_fd_install(target_proc, target_fd, file);
fp->handle = target_fd;
} break;
default:
return_error = BR_FAILED_REPLY;
goto err_bad_object_type;
}
}
if (reply) {
binder_pop_transaction(target_thread, in_reply_to);
} else if (!(t->flags & TF_ONE_WAY)) {
t->need_reply = 1;
t->from_parent = thread->transaction_stack;
thread->transaction_stack = t;
} else {
if (target_node->has_async_transaction) {
target_list = &target_node->async_todo;
target_wait = NULL;
} else
target_node->has_async_transaction = 1;
}
t->work.type = BINDER_WORK_TRANSACTION;
list_add_tail(&t->work.entry, target_list);
tcomplete->type = BINDER_WORK_TRANSACTION_COMPLETE;
list_add_tail(&tcomplete->entry, &thread->todo);
if (target_wait)
wake_up_interruptible(target_wait);
return;
}
2.4 响应协议
binder响应码,是用enum binder_driver_return_protocol来定义的,是binder设备向应用程序回复的消息,,应用程序包含Client端和Server端,以BR_开头,总18条;
| 响应码 | 参数类型 | 作用 |
|---|---|---|
| BR_ERROR | __s32 | 操作发生错误 |
| BR_OK | 无参数 | 操作完成 |
| BR_NOOP | 无参数 | 不做任何事 |
| BR_SPAWN_LOOPER | 无参数 | 创建新的Looper线程 |
| BR_TRANSACTION | binder_transaction_data | Binder驱动向Server端发送请求数据 |
| BR_REPLY | binder_transaction_data | Binder驱动向Client端发送回复数据 |
| BR_TRANSACTION_COMPLETE | 无参数 | 对请求发送的成功反馈 |
| BR_DEAD_REPLY | 无参数 | 回复失败,往往是线程或节点为空 |
| BR_FAILED_REPLY | 无参数 | 回复失败,往往是transaction出错导致 |
| BR_INCREFS | binder_ptr_cookie | binder_ref弱引用加1操作(Server端) |
| BR_DECREFS | binder_ptr_cookie | binder_ref弱引用减1操作(Server端) |
| BR_ACQUIRE | binder_ptr_cookie | binder_ref强引用加1操作(Server端) |
| BR_RELEASE | binder_ptr_cookie | binder_ref强引用减1操作(Server端) |
| BR_DEAD_BINDER | binder_uintptr_t(指针) | Binder驱动向client端发送死亡通知 |
| BR_CLEAR_DEATH_NOTIFICATION_DONE | binder_uintptr_t(指针) | BC_CLEAR_DEATH_NOTIFICATION命令对应的响应码 |
| BR_ACQUIRE_RESULT | - | - |
| BR_ATTEMPT_ACQUIRE | - | - |
| BR_FINISHED | - | - |
BR_SPAWN_LOOPER:binder驱动已经检测到进程中没有线程等待即将到来的事务。那么当一个进程接收到这条命令时,该进程必须创建一条新的服务线程并注册该线程,在接下来的响应过程会看到何时生成该响应码。
BR_TRANSACTION_COMPLETE:当Client端向Binder驱动发送BC_TRANSACTION命令后,Client会收到BR_TRANSACTION_COMPLETE命令,告知Client端请求命令发送成功;对于Server向Binder驱动发送BC_REPLY命令后,Server端会收到BR_TRANSACTION_COMPLETE命令,告知Server端请求回应命令发送成功。
BR_DEAD_REPLY: 当应用层向Binder驱动发送Binder调用时,若Binder应用层的另一个端已经死亡,则驱动回应BR_DEAD_BINDER命令。
BR_FAILED_REPLY: 当应用层向Binder驱动发送Binder调用时,若transaction出错,比如调用的函数号不存在,则驱动回应BR_FAILED_REPLY。
2.5 响应过程
响应处理过程是通过binder_thread_read()方法,该方法根据不同的binder_work->type以及不同状态,生成相应的响应码。
binder_thread_read(){
//当已使用字节数为0时,将BR_NOOP响应码放入指针ptr
if (*consumed == 0) {
if (put_user(BR_NOOP, (uint32_t __user *)ptr))
return -EFAULT;
ptr += sizeof(uint32_t);
}
retry:
wait_for_proc_work = thread->transaction_stack == NULL &&
list_empty(&thread->todo);
if (wait_for_proc_work) {
binder_set_nice(proc->default_priority);
if (non_block) {
if (!binder_has_proc_work(proc, thread))
ret = -EAGAIN;
} else
ret = wait_event_freezable_exclusive(proc->wait, binder_has_proc_work(proc, thread));
} else {
if (non_block) {
if (!binder_has_thread_work(thread))
ret = -EAGAIN;
} else
//等待客户端的请求
ret = wait_event_freezable(thread->wait, binder_has_thread_work(thread));
}
if (ret)
return ret; //对于非阻塞的调用,直接返回
while (1) {
当&thread->todo和&proc->todo都为空时,goto到retry标志处,否则往下执行:
struct binder_transaction_data tr;
struct binder_transaction *t = NULL;
switch (w->type) {
case BINDER_WORK_TRANSACTION:
t = container_of(w, struct binder_transaction, work);
break;
case BINDER_WORK_TRANSACTION_COMPLETE:
cmd = BR_TRANSACTION_COMPLETE;
put_user(cmd, (uint32_t __user *)ptr); //将cmd写入*ptr
list_del(&w->entry);
kfree(w);
break;
case BINDER_WORK_NODE:
struct binder_node *node = container_of(w, struct binder_node, work);
uint32_t cmd = BR_NOOP;
if (weak && !node->has_weak_ref) {
cmd = BR_INCREFS;
cmd_name = "BR_INCREFS";
node->has_weak_ref = 1;
node->pending_weak_ref = 1;
node->local_weak_refs++;
} else if (strong && !node->has_strong_ref) {
cmd = BR_ACQUIRE;
cmd_name = "BR_ACQUIRE";
node->has_strong_ref = 1;
node->pending_strong_ref = 1;
node->local_strong_refs++;
} else if (!strong && node->has_strong_ref) {
cmd = BR_RELEASE;
cmd_name = "BR_RELEASE";
node->has_strong_ref = 0;
} else if (!weak && node->has_weak_ref) {
cmd = BR_DECREFS;
cmd_name = "BR_DECREFS";
node->has_weak_ref = 0;
}
if (cmd != BR_NOOP) {
put_user(cmd, (uint32_t __user *)ptr);
ptr += sizeof(uint32_t);
put_user(node->ptr, (binder_uintptr_t __user *)ptr);
ptr += sizeof(binder_uintptr_t);
(put_user(node->cookie,(binder_uintptr_t __user *)ptr);
ptr += sizeof(binder_uintptr_t);
}else{
list_del_init(&w->entry);
if (!weak && !strong) {
rb_erase(&node->rb_node, &proc->nodes);
kfree(node);
}
}
break;
case BINDER_WORK_DEAD_BINDER:
case BINDER_WORK_DEAD_BINDER_AND_CLEAR:
case BINDER_WORK_CLEAR_DEATH_NOTIFICATION:
death = container_of(w, struct binder_ref_death, work);
if (w->type == BINDER_WORK_CLEAR_DEATH_NOTIFICATION)
cmd = BR_CLEAR_DEATH_NOTIFICATION_DONE;
else
cmd = BR_DEAD_BINDER;
put_user(cmd, (uint32_t __user *)ptr);
ptr += sizeof(uint32_t);
put_user(death->cookie,(binder_uintptr_t __user *)ptr);
ptr += sizeof(binder_uintptr_t);
if (w->type == BINDER_WORK_CLEAR_DEATH_NOTIFICATION) {
list_del(&w->entry);
kfree(death);
} else
list_move(&w->entry, &proc->delivered_death);
if (cmd == BR_DEAD_BINDER)
goto done; //跳转到done标识符
if (t->buffer->target_node) {
struct binder_node *target_node = t->buffer->target_node;
tr.target.ptr = target_node->ptr;
tr.cookie = target_node->cookie;
cmd = BR_TRANSACTION;
} else {
tr.target.ptr = 0;
tr.cookie = 0;
cmd = BR_REPLY;
}
//根据binder_transaction结构体来赋值binder_transaction_data数据,省略
put_user(cmd, (uint32_t __user *)ptr);
ptr += sizeof(uint32_t);
copy_to_user(ptr, &tr, sizeof(tr)); //将tr数据传输到用户空间
ptr += sizeof(tr);
if (cmd == BR_TRANSACTION && !(t->flags & TF_ONE_WAY)) {
t->to_parent = thread->transaction_stack;
t->to_thread = thread;
thread->transaction_stack = t;
} else {
t->buffer->transaction = NULL;
kfree(t);
}
break;
}
done:
*consumed = ptr - buffer;
//当满足请求线程加已准备线程数等于0,已启动线程数小于最大线程数(15),
//且looper状态为已注册或已进入时创建新的线程。
if (proc->requested_threads + proc->ready_threads == 0 &&
proc->requested_threads_started < proc->max_threads &&
(thread->looper & (BINDER_LOOPER_STATE_REGISTERED |
BINDER_LOOPER_STATE_ENTERED))) {
proc->requested_threads++;
// 生成BR_SPAWN_LOOPER命令,用于创建新的线程
put_user(BR_SPAWN_LOOPER, (uint32_t __user *)buffer);
}
return 0;
}
当transaction堆栈为空,且线程todo链表为空,且non_block=false时,意味着没有任何事务需要处理的,会进入等待客户端请求的状态。当有事务需要处理时便会进入循环处理过程,并生成相应的响应码。
在Binder驱动层,只有在进入binder_thread_read()方法时,同时满足以下条件,
才会生成BR_SPAWN_LOOPER命令,当用户态进程收到该命令则会创建新线程:
- binder_proc的requested_threads线程数为0;
- binder_proc的ready_threads线程数为0;
- binder_proc的requested_threads_started个数小于15(即最大线程个数);
- binder_thread的looper状态为BINDER_LOOPER_STATE_REGISTERED或BINDER_LOOPER_STATE_ENTERED。
那么在哪里处理响应码呢? 通过前面的Binder通信协议图,可以知道处理响应码的过程是在用户态处理,即后续文章会讲到的用户空间IPCThreadState类中的IPCThreadState::waitForResponse()和IPCThreadState::executeCommand()两个方法共同处理Binder协议中的18个响应码。
2.6 通信模型
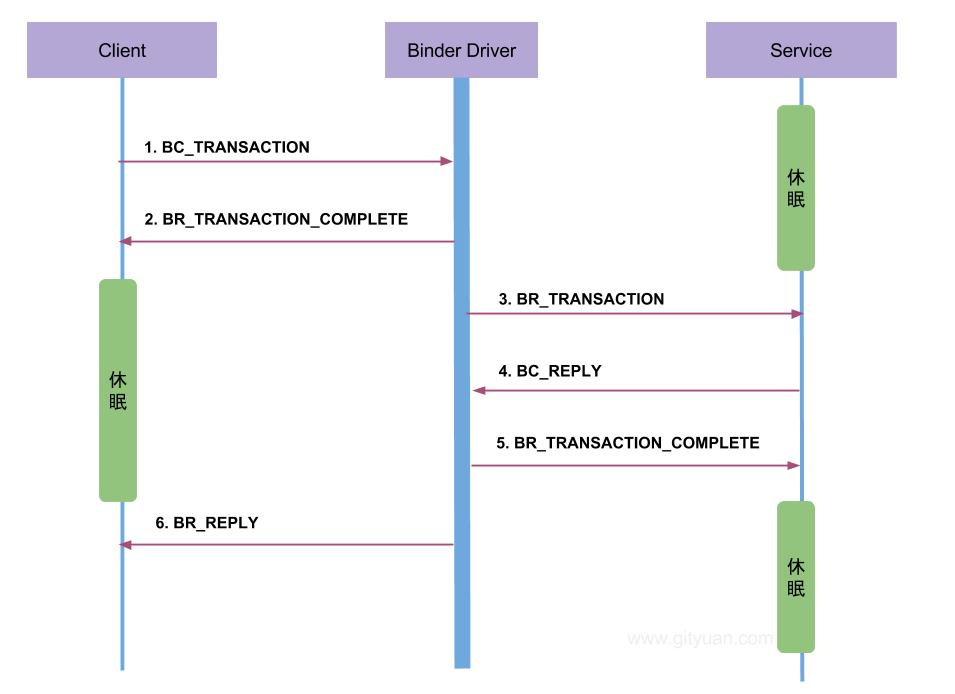
下面列举一次完整的Binder通信过程:
三、Binder内存
3.1 Binder机制
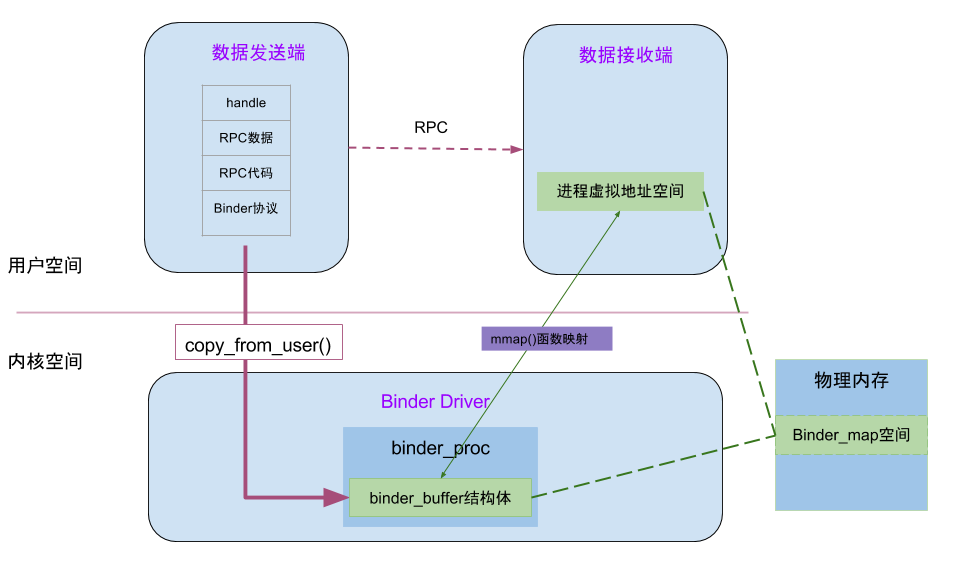
在上一篇文章从代码角度阐释了binder_mmap(),这也是Binder进程间通信效率高的核心机制所在,如下图:
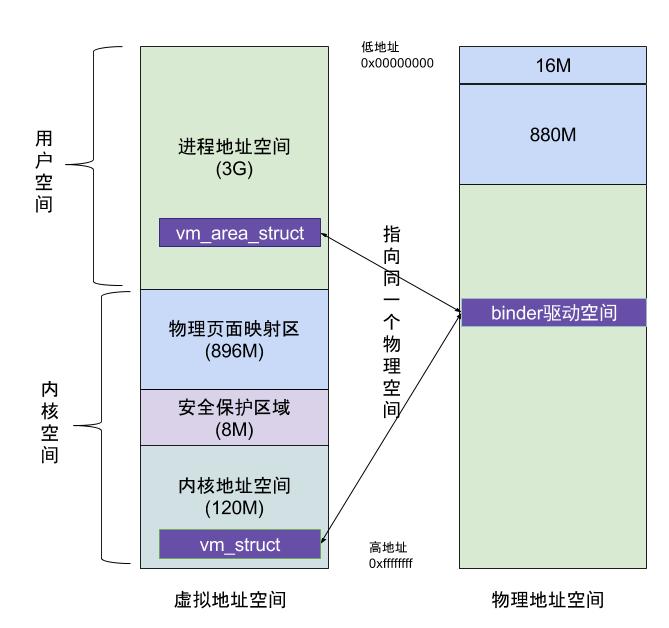
虚拟进程地址空间(vm_area_struct)和虚拟内核地址空间(vm_struct)都映射到同一块物理内存空间。当Client端与Server端发送数据时,Client(作为数据发送端)先从自己的进程空间把IPC通信数据copy_from_user拷贝到内核空间,而Server端(作为数据接收端)与内核共享数据,不再需要拷贝数据,而是通过内存地址空间的偏移量,即可获悉内存地址,整个过程只发生一次内存拷贝。一般地做法,需要Client端进程空间拷贝到内核空间,再由内核空间拷贝到Server进程空间,会发生两次拷贝。
对于进程和内核虚拟地址映射到同一个物理内存的操作是发生在数据接收端,而数据发送端还是需要将用户态的数据复制到内核态。到此,可能有读者会好奇,为何不直接让发送端和接收端直接映射到同一个物理空间,那样就连一次复制的操作都不需要了,0次复制操作那就与Linux标准内核的共享内存的IPC机制没有区别了,对于共享内存虽然效率高,但是对于多进程的同步问题比较复杂,而管道/消息队列等IPC需要复制2两次,效率较低。这里就不先展开讨论Linux现有的各种IPC机制跟Binder的详细对比,总之Android选择Binder的基于速度和安全性的考虑。
下面这图是从Binder在进程间数据通信的流程图,从图中更能明了Binder的内存转移关系。
3.2 内存分配
Binder内存分配方法通过binder_alloc_buf()方法,内存管理单元为binder_buffer结构体。
static struct binder_buffer *binder_alloc_buf(struct binder_proc *proc,
size_t data_size, size_t offsets_size, int is_async)
{
struct rb_node *n = proc->free_buffers.rb_node;
struct binder_buffer *buffer;
size_t buffer_size;
struct rb_node *best_fit = NULL;
void *has_page_addr;
void *end_page_addr;
size_t size;
if (proc->vma == NULL) {
return NULL; //虚拟地址空间为空,直接返回
}
size = ALIGN(data_size, sizeof(void *)) + ALIGN(offsets_size, sizeof(void *));
if (size < data_size || size < offsets_size) {
return NULL; //非法的size
}
if (is_async && proc->free_async_space < size + sizeof(struct binder_buffer)) {
return NULL; // 剩余可用的异步空间,小于所需的大小
}
while (n) { //从binder_buffer的红黑树从,查找大小相等的buffer块
buffer = rb_entry(n, struct binder_buffer, rb_node);
buffer_size = binder_buffer_size(proc, buffer);
if (size < buffer_size) {
best_fit = n;
n = n->rb_left;
} else if (size > buffer_size)
n = n->rb_right;
else {
best_fit = n;
break;
}
}
if (best_fit == NULL) {
return NULL; //内存分配失败,地址空间为空
}
if (n == NULL) {
buffer = rb_entry(best_fit, struct binder_buffer, rb_node);
buffer_size = binder_buffer_size(proc, buffer);
}
has_page_addr =(void *)(((uintptr_t)buffer->data + buffer_size) & PAGE_MASK);
if (n == NULL) {
if (size + sizeof(struct binder_buffer) + 4 >= buffer_size)
buffer_size = size;
else
buffer_size = size + sizeof(struct binder_buffer);
}
end_page_addr = (void *)PAGE_ALIGN((uintptr_t)buffer->data + buffer_size);
if (end_page_addr > has_page_addr)
end_page_addr = has_page_addr;
if (binder_update_page_range(proc, 1,
(void *)PAGE_ALIGN((uintptr_t)buffer->data), end_page_addr, NULL))
return NULL;
rb_erase(best_fit, &proc->free_buffers);
buffer->free = 0;
binder_insert_allocated_buffer(proc, buffer);
if (buffer_size != size) {
struct binder_buffer *new_buffer = (void *)buffer->data + size;
list_add(&new_buffer->entry, &buffer->entry);
new_buffer->free = 1;
binder_insert_free_buffer(proc, new_buffer);
}
buffer->data_size = data_size;
buffer->offsets_size = offsets_size;
buffer->async_transaction = is_async;
if (is_async) {
proc->free_async_space -= size + sizeof(struct binder_buffer);
}
return buffer;
}
3.3 内存释放
binder_free_buf
static void binder_free_buf(struct binder_proc *proc,
struct binder_buffer *buffer)
{
size_t size, buffer_size;
buffer_size = binder_buffer_size(proc, buffer);
size = ALIGN(buffer->data_size, sizeof(void *)) +
ALIGN(buffer->offsets_size, sizeof(void *));
binder_debug(BINDER_DEBUG_BUFFER_ALLOC,
"%d: binder_free_buf %p size %zd buffer_size %zd\n",
proc->pid, buffer, size, buffer_size);
if (buffer->async_transaction) {
proc->free_async_space += size + sizeof(struct binder_buffer);
binder_debug(BINDER_DEBUG_BUFFER_ALLOC_ASYNC,
"%d: binder_free_buf size %zd async free %zd\n",
proc->pid, size, proc->free_async_space);
}
binder_update_page_range(proc, 0,
(void *)PAGE_ALIGN((uintptr_t)buffer->data),
(void *)(((uintptr_t)buffer->data + buffer_size) & PAGE_MASK),
NULL);
rb_erase(&buffer->rb_node, &proc->allocated_buffers);
buffer->free = 1;
if (!list_is_last(&buffer->entry, &proc->buffers)) {
struct binder_buffer *next = list_entry(buffer->entry.next,
struct binder_buffer, entry);
if (next->free) {
rb_erase(&next->rb_node, &proc->free_buffers);
binder_delete_free_buffer(proc, next); //调用下方
}
}
if (proc->buffers.next != &buffer->entry) {
struct binder_buffer *prev = list_entry(buffer->entry.prev,
struct binder_buffer, entry);
if (prev->free) {
binder_delete_free_buffer(proc, buffer); //调用下方
rb_erase(&prev->rb_node, &proc->free_buffers);
buffer = prev;
}
}
binder_insert_free_buffer(proc, buffer);
}
binder_delete_free_buffer
static void binder_delete_free_buffer(struct binder_proc *proc,
struct binder_buffer *buffer)
{
struct binder_buffer *prev, *next = NULL;
int free_page_end = 1;
int free_page_start = 1;
BUG_ON(proc->buffers.next == &buffer->entry);
prev = list_entry(buffer->entry.prev, struct binder_buffer, entry);
BUG_ON(!prev->free);
if (buffer_end_page(prev) == buffer_start_page(buffer)) {
free_page_start = 0;
if (buffer_end_page(prev) == buffer_end_page(buffer))
free_page_end = 0;
binder_debug(BINDER_DEBUG_BUFFER_ALLOC,
"%d: merge free, buffer %p share page with %p\n",
proc->pid, buffer, prev);
}
if (!list_is_last(&buffer->entry, &proc->buffers)) {
next = list_entry(buffer->entry.next,
struct binder_buffer, entry);
if (buffer_start_page(next) == buffer_end_page(buffer)) {
free_page_end = 0;
if (buffer_start_page(next) ==
buffer_start_page(buffer))
free_page_start = 0;
binder_debug(BINDER_DEBUG_BUFFER_ALLOC,
"%d: merge free, buffer %p share page with %p\n",
proc->pid, buffer, prev);
}
}
list_del(&buffer->entry);
if (free_page_start || free_page_end) {
binder_debug(BINDER_DEBUG_BUFFER_ALLOC,
"%d: merge free, buffer %p do not share page%s%s with %p or %p\n",
proc->pid, buffer, free_page_start ? "" : " end",
free_page_end ? "" : " start", prev, next);
binder_update_page_range(proc, 0, free_page_start ?
buffer_start_page(buffer) : buffer_end_page(buffer),
(free_page_end ? buffer_end_page(buffer) :
buffer_start_page(buffer)) + PAGE_SIZE, NULL);
}
}
binder_transaction_buffer_release
binder_transaction_buffer_release(){
case BINDER_TYPE_BINDER:
binder_dec_node(node, 1, 0);
case BINDER_TYPE_WEAK_BINDER:
binder_dec_node(node, 0, 0);
case BINDER_TYPE_HANDLE:
binder_dec_ref(ref, 1);
case BINDER_TYPE_WEAK_HANDLE:
binder_dec_ref(ref, 0);
case BINDER_TYPE_FD:
task_close_fd(proc, fp->handle);
}
上述涉及的方法的功能如下:
| 强/弱引用操作函数 | 功能 |
|---|---|
| binder_inc_ref(ref,0,NULL) | binder_ref->weak++ |
| binder_inc_ref(ref,1,NULL) | binder_ref->strong++,或binder_node->internal_strong_refs++ |
| binder_dec_ref(&ref,0) | binder_ref->weak– |
| binder_dec_ref(&ref,1) | binder_ref->strong–, 或binder_node->internal_strong_refs– |
| binder_dec_node(node, 0, 0) | binder_node->pending_weak_ref = 0,且binder_node->local_weak_ref– |
| binder_dec_node(node, 1, 0) | binder_node->pending_strong_ref = 0,且binder_node->local_strong_ref– |